– the good, the bad and the ugly
A usual morning routine of inspecting my “What’s New at AWS” RSS feed turned into an interesting internal conflict for a minute – AWS launched the capability to attach an Amazon EFS access point to an AWS Lambda function. For a second, jumping for joy thinking about all the possibilities and the next moment wondering about all the bad practices or anti-patterns that could mutate from this shiny new toy in the builder toolkit.
This blog will focus on a few patterns or best practices around AWS Lambda and the use of filesystems and datastores, when to use this new Amazon Elastic File System tool in the builder toolbox and possibly when not to. Some interesting stats will also make an appearance.
Before we dive in, what is Amazon Elastic File System or Amazon EFS, you may ask? The short answer, it is a fully managed NFS filesystem, that automatically scales with your data, offers impressive performance throughput, and virtually unlimited storage.
In short, the EFS + Lambda announcement means that you now have a shared block-level filesystem available to your AWS Lambda functions. Fantastic! Let’s dive into how to get started by looking at it through the Good, the Bad and the Ugly lenses.
TL;DR
Amazon EFS integration with AWS Lambda resolves several real-world pain points on larger file processing use cases in AWS Lambda, however, should be used with caution and in conjunction with experience-based design decisions.
Unless used with caution, simply adding an Amazon EFS access point in an attempt to solve an olden day’s batch processing problem in a serverless manner may land you in a world of trouble down the road. Should you ever talk to a team member who is scheduling an AWS Lambda function every 2-10 minutes to check if there is a new file on EFS to process – please arrange an intervention! 🙂
The Good
Several noteworthy performance characteristics:
- Since the announcement of AWS Lambda VPC ENI improvements in 2019 – Lambda cold starts have not been making headlines. The great news is that the performance of cold starts is not noticeably impacted by attaching an EFS file system – several cold-start tests average at less than 20ms difference, if any at all.
- Read access of files through EFS vs. S3 is an interesting game of rock-paper-scissors. Operating System (FireCracker) file caching for NFS seems to come into the equation when accessing a static file over and over (from the same warm container) – this performance beats S3 access any day of the week. In contrast, where frequently changing or random files are accessed, the performance difference between S3 and EFS is less impressive – with S3 winning at times. A 400MB file copied from EFS takes approx. 5,500ms first round, with the second request on a warm container coming in at 400ms. The same file from S3 (same region, with Gateway Endpoint) takes 5,100ms on average.
- Write access performance between S3 and EFS follow a similar pattern to random file access at approx. 5,500ms for 400MB files.
- Cost of EFS vs. S3 – hundreds and thousands of put/get operations against S3 may start to feature on your AWS invoice. Normally only a small number in comparison but depending on the use-case for file-access, EFS may be a cheaper alternative as you pay for storage allocation only, with a lower data-transfer cost.
- We will not be comparing EFS throughput/IO/latency against ElastiCache, DynamoDB or RDS – as these datastores have a different purpose.
A few noteworthy use-cases for EFS:
- Data Consistency in EFS vs. S3 – now here EFS is a clear winner. With open-after-close consistency, you are guaranteed that the next iteration of a process (Lambda or EC2) will access the most recent object. The same cannot be said for S3 and its eventual-consistency-model (except for first write of course).
- Large file processing – our Lambda runtime offers 512MB of /tmp space and with 15mins of execution time. It is fair to say that a Lambda (3GB memory) could churn through much more than 512MB (txt, video, image) – mix it up, enhance it and write it back out. Previously, this was not possible as the file would need to be copied locally to the Lambda container from S3.
- Large dependencies – perhaps a less frequent use-case, however still relevant as Lambda offers a maximum deployment package size of 250MB. Serverless Machine Learning Inferencing have been a hot topic of late and in many cases the ML-model exceeds the 250MB or at times the 512MB /tmp size of an AWS Lambda function. This is where EFS shines, offering much larger ML-models and other dependencies to be referenced. The downside here is the warm-vs-cold Lambda thorn, compounded by an unknown (my knowledge) Lambda OS (FireCracker) NFS file cache limit – thus the benefit of OS caching may not be available for multi-GB files.
The Bad – or common pitfalls to avoid for best practice
- Amazon EFS is a regional service (durable and available), but the mount targets are Availability Zone specific. Best practice is for the EFS file system to have mount targets in all AZs that you plan to execute the Lambda functions in – and then to have the VPC-Lambda functions deploy/execute in all available AZs.
- Using EFS forces the Lambda to be VPC connected – not a showstopper as this would be the same for most datastores like RDS, ElastiCache and a few others. However, if you are using EFS where S3 would be just as suitable as an asset storage location and you have no other need to run the Lambda inside a VPC – perhaps EFS should be reconsidered.
- Inter Process or Inter Lambda State Management – my recommendation is don’t. Process state should be small bits of information that indicate the status of a job or point to the location of partly processed job assets. State belongs in sub-millisecond stores such as DynamoDB or ElastiCache (SNS or SQS even). If you do not already have an ElastiCache cluster at your disposal and money over architecture-best-practice is a concern – DynamoDB is a very good or just as good alternative for durable state management.
- Using EFS (or S3) for very small files/data payloads to perform batch processing like in the olden days. This is where knowledge and expertise are needed to make the best-practice, cloud native architecture decisions. Large volumes of small payloads (1-1MB) belong in streaming or event-driven architectures. SNS, SQS or Kinesis is the swiss-army knife of such processing requirements and do not belong in EFS.
- Where both large object size and velocity (frequency) are at play, the same pattern as above should be used. A small payload to manage process-state being event-driven in SNS, SQS or Kinesis, and only the large assets (videos) stored on EFS.
The Ugly
- If your organization is predominantly a Windows environment, with .NET applications and IIS needing to make use of or produce data on EFS (which in turn will be accessed by AWS Lambda), the bad news is that Amazon Elastic File System does not play well with Windows – so any integration here is not possible.
- IO vs. storage size – EFS offer you throughput (the IO) based on the size of the file system, with a yardstick of 50KiB/s per 1GB of file system – so even with 1 TeraByte of file system data, a theoretical 50MiB/s is the 24/7 available throughput. In a busy lambda processing environment working with large files (because that why we chose EFS) this will be exhausted very quickly – slowing down Lambdas, failed processing, increased Lambda execution cost, etc. EFS do offer a second option to optimise throughput called Max I/O, earmarked for thousands of instances (read Lambda) connected to the file system, however this feature impacts on the latency of each request.
- A rough US$7 per MB/s-Month buys you guaranteed EFS throughput, irrespective of your file system size, which may soon add up in a busy Lambda environment with frequently changing files (read) or large write operations.
Storage alternatives
Lambda was designed to process events as part of an event-driven, micro-services architecture – processing smaller payloads at scale. Since launch, the little Lambda engine have been pushed to its limits, with customers still asking for longer run-times. 15 minutes offer you a great deal of power, but you should re-consider if these limits are being reached (ECS Fargate may be more appropriate)
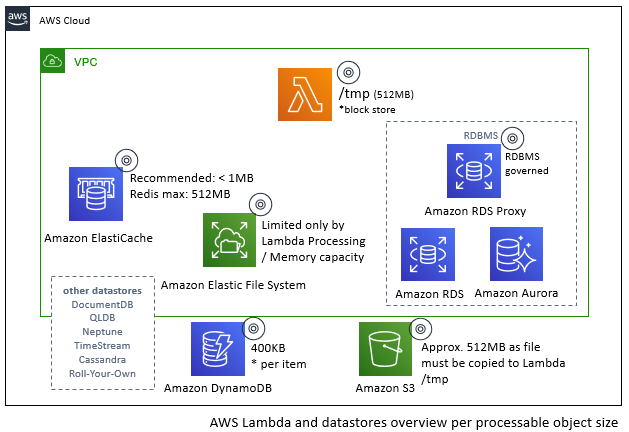
The diagram below offers an overview of what is achievable from a data object processing perspective.
Quick Setup Guide
The steps below will guide you through a short list of setup instructions to highlight the simplicity, however, the blog is not intended to be a detailed instruction guide – a reference to such a guide is given further down. A precondition is an AWS Account and a VPC to deploy the services into:
- Create an Amazon EFS file system (console instructions below)
- Select the VPC and subnets/availability zones of choice (use default VPC and Security Groups)
- Keep the defaults and for simplicity of IAM setup – for now do not use encryption
- Add an Access Point (dependency for the Lambda function)
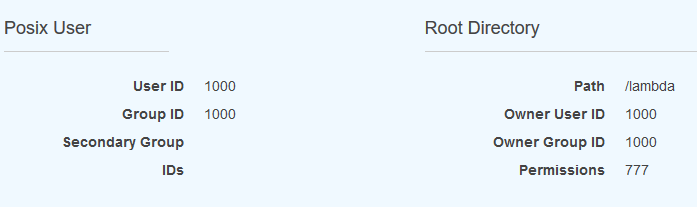
- Make note of the path – as this is the folder/directory that will be created in your filesystem, and acts as the root for any client that connect using this Access Point. So, if you have EC2 instances that write data to the EFS filesystem, it needs to be placed in the “/lambda” directory for your function to access it.
- Few more clicks and you have an Amazon EFS file system ready to go
2. To the world with some ls and cp commands, you will need to setup an Amazon EC2 instance, hook it up to the EFS file system and SSH into the host… easy to do, but consider this optional for now.
3. A specific IAM Role with EFS and VPC permissions is required
- Create a new IAM role
- Attached the following managed policies AWSLambdaVPCAccessExecutionRole and AmazonElasticFileSystemClientFullAccess (remember to tweak these as needed in a production environment)
4. Create a Lambda function (console)
- Give it a name “eftTestFunction”
- Select the previously created IAM role
- And choose your poison – or runtime (I have a bit of Python 3.8 code below)
- << Create the function >>
5. Configure the Lambda function
- Attach it to a VPC – same VPC and subnets/availability zones and security groups as your EFS file system mount targets above (noting in a production setup this is not considered best practice.
- Attach the EFS file system (a bit further down in the configuration page) – select the EFS and the created Access Point.
- The important part – the mount point “/mnt/lambda-efs” – this is the location or directory that will be available in the Lambda function which maps to the EFS filesystem and the selected access point “Path”
- Path and Mounting Point explained: In Lambda you access the files as (/mnt/lambda-efs/aFile.png), directly on EFS, the path from the root is (/lambda/aFile.png), Where “/lambda” is defined by the Access Point definition.
import json
def lambda_handler(event, context):
# open file for append
f = open('/mnt/lambda-efs/lambda-processing-trace.txt', 'a')
writeLength = f.write('TraceID: '+context.aws_request_id + "\r\n")
f.close()
#read contents and print
f = open('/mnt/lambda-efs/lambda-processing-trace.txt', 'r')
file_contents = f.read()
print (file_contents)
f.close()
return {
'statusCode': 200,
'body': json.dumps('File Processing Complete - Data Written')
}The simple python code above creates a file on the EFS file system (under EFS path /lambda) writes to it and prints the contents thereof to the console – thus each time you run the lambda function; the contents will increase with the trace-id of the previous executions.
Should you be in the position where the Lambda function shares state or update shared files, be sure to include file locking patterns in all applications and Lambda functions that may access the file(s), as files are not locked by default by most file-IO managers and only the last Lambda who had the file open for writing will win. A better implementation (in Python) of such a function is provided below.
A better implementation (in Python) of such a function is provided below.
import json
import os
import fcntl #file control module
import random
import time
class LockException(Exception): pass
def lambda_handler(event, context):
try:
with open('/mnt/lambda-efs/file.txt', 'a') as myfile:
#lock the file
fcntl.flock(myfile, fcntl.LOCK_EX | fcntl.LOCK_NB)
myfile.write('TraceID (1): '+context.aws_request_id + "\r\n")
#and now unlock
fcntl.flock(myfile, fcntl.LOCK_UN)
myfile.close()
responseMsg = 'File Processing Success - Data Written'
responseCode = 200
except:
print ('File Lock Failed')
myfile.close()
raise LockException('Unknown error')
return {
'statusCode': responseCode,
'body': json.dumps(responseMsg)
}Should you be curious, or if you had trouble setting up the sandbox, have a look at this detailed blog post from the AWS Serverless team. Need to explore the world of file-locking (in Python)? Here is a good start.
Lambda execution control retries may need to be considered very closely when using EFS. When consistency of files and locking is a factor in your decision to attach EFS to your Lambda function – you should ask yourself, “if my Lambda automatically re-executes in 2 minutes because it failed, could not obtain a lock or some other reason – what could go wrong?”. The same holds true for other integrations, however serverless, microservices and event-driven architectures should expect failure and ensure they are not sensitive to such occurrences (and ideally be idempotent by design).